Have you been wondering why are all your favorite bloggers are going crazy for automatic clustering? Well it is a fun visual technique to see which matches belong to which family line by making a chart with your matches across both the top and side, grouping them by who matches who, and then coloring those boxes in. This creates visual clusters which will roughly correspond to your great grandparents or their parents.
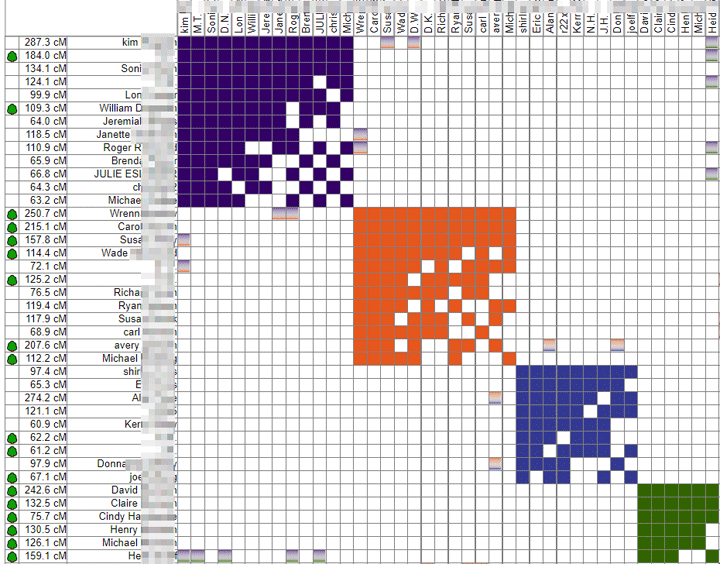
My perfect cousin has many matches on all her great grandparent lines (green is my Munson side) so I used her to showcase the new DNAgedcom clustering above. Notice how similar it is to her cluster from Genetic Affairs shown in my previous blog about that site and tool.
Here are all the new ways to cluster our DNA matches:
- DNAgedcom now has a clustering tool in their client (DGC) which uses your ancestry match list and ICW files (described in detail in the read more below)
- Genetic Affairs has Ancestry
clustering working again
- DNApainter created a tool to create a CSV from the Genetic Affairs html cluster file. Some of us love to use spreadsheets.
- Andy Lee of Family History Fanatics figured out how to take an autosomal match matrix from GEDmatch and cluster it in a spreadsheet program, Click here for that video – the explanation starts just after 42 minutes and this is really fun!
- Rumor has it that GEDmatch may add automatic clustering sometime in the new year…
All of this is based on the method developed by Dana Leeds to organize your matches which is easy and simple to do. Click here for her blog about that.
Read on for how I used the new DNAgedcom clustering tool for myself and my brother, where I know all our great grandparents.