In recent discussions with a few of my genetic genealogy students, I discovered that many need some help with understanding how to use spreadsheets. So I went looking and found a series of excellent youtube videos that even taught me a few things. Here is the first one in the series.
He uses OpenOffice Calc which is free and happens to be the spreadsheet that I use.
The basic idea of a spreadsheet is to make a list of things that you want to keep track of, with the information about each of them listed next to them in columns. As you use it, you may decide to insert more columns, the things you are tracking for each, or more rows, the items you are interested in. You can also delete any of these and best of all, sort them.
For DNA tracking purposes, the only other important function to understand is formatting cells so that the numbers don’t surprise you by turning into dates or fractions when you do not want them to. Click here for a recent article claiming that 20% of scientific papers on genes contain gene name conversion errors because of this type of reformatting!
Personally I reformat the start and stop points to have commas so I can read the numbers more easily and make the centimorgans column (genetic distance) default to two decimal places so that they line up well. I also change the font to Arial.
Suppose you want to keep your match list in a spreadsheet. There are many articles on this blog that explain how to do that. Use the tag DNA spreadsheets to find them by clicking here – http://blog.kittycooper.com/tag/dna-spreadsheet/
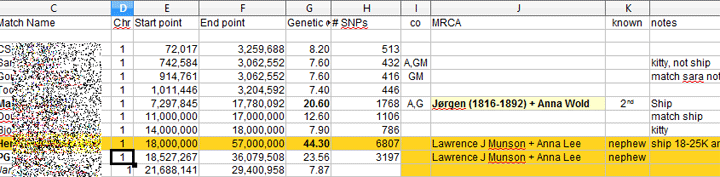
Extract from my Dad’s Match List Spreadsheet
Start with the match list of DNA segments from the company you tested at. If you have only tested at Ancestry, then upload your results to GEDmatch.com and read my article about how to make a master spreadsheet using the matching segment tool at GEDmatch. You may wish to add columns like MRCA (most recent common ancestor), relationship, and notes like I have done in my Dad’s shown above.
Both 23andme and Family Tree DNA have a way you can download all your matches with their matching segment data or more easily you can use the tools at DNAgedcom.com to do that.
Another spreadsheet you might want to keep would be one to keep track of your DNA correspondence, perhaps with columns for their name (keeping the surname separate so you can sort by it), where they tested, how much DNA they share, their email address, gedmatch number, and occasionally even a phone number.
There are sample spreadsheets for both of these in my downloads area. Also have a look at the pictures you can make from these spreadsheets using my tools.

Segment Mapper Tool generated Chromosome Map of Kitty’s Closest Matches
If they do not have a spreadsheet program, I suggest using Google Sheets, and Google Docs. It has many advantages including being able to share with others.
I try to keep almost everything I want to have handy in one spreadsheet. So I have columns for email; cousinship; Sent and Reply (to keep track of emails or messages I’ve sent (by date, so I can find them easily if necessary) and the ones received; Ahnentafel number of MRCA; Tree URL (pasting a link to their Tree in this cell lets me easily refer back to their Tree); Date (I try to enter a date for each Match as I add them (or use FTDNA’s date), so I can sort and easily figure out the most recent add); Kin (in this column I put the initials of my closest known kin who also Matches on this segment – color-coded this highlights the “side” this segment is on); side (M or P – this is necessary to use Kitty’s chromosome tool; it also lets you sort your spreadsheet to separate the Maternal and Paternal chromosomes; Donor (if you keep a spreadsheet for more than one person); GEDmatch number; GEDmatch generation estimate; 23andMe link (this hyperlink (from a download of all shared segments) takes you directly to the Match with an InCommonWith list – very handy); Y-DNA and mtDNA haplogroup (if you track or use them, I don’t find them very useful); Notes or Remarks (to remember anything else that’s important to you). If I don’t know an MRCA, I use the MRCA column to note anything interesting about the Match (Adopted, Irish, Jewish, all-North Carolina, UK, No Tree, etc. – it helps me)
And Jim’s guest blog here is one of the best on spreadsheeting for DNA at http://blog.kittycooper.com/2014/01/organizing-your-autosomal-dna-information-with-a-spreadsheet/
I use Genomate Pro. Everything in one place. It’s no more complicated to learn how to import data than it is to manipulate spreadsheets.
I manage kits for other relatives, including my mother, my brother and my aunt. Should I keep a full separate spreadsheet for each person?
Hi Linda – I like to keep a spreadsheet for each person but Jim likes to keep them all together. This is really a matter of personal preference.
Bonnie, Genomate Pro sounds like an incredibly worthwhile package. Personally I like to have the flexibility of spreadsheeting my way but then that is how i started. If anyone out there wants to do a guest post on Genomate and Genomate Pro I would be happy to publish it.
Pingback: Favorite Reads of the Week: 10 December 2016 – Christmas Letters, Oliebolen, WWII Research Guide – Family Locket
So you have downloaded 23,367 matches from AncestryDNA and put them into a spreadsheet. How do you know which line they belong to? You don’t but those matches will share matches with you and others. Turning those shared matches into a group is what you need to do.
The best way to start is to use your top 200 users and try and place these into a group, which translates into a particular family line.
To do this create 2 columns, the first numbering the matches as they are (#) and the second column numbered when sorted (Srtd.). The paste the Top 200 into the document, pasting at cell C1.
With most spreadsheets there is always a problem with making a mistake when you are using that data, by sorting a column for instance. One way of lessening those mistakes, is to number the first column, so that if you want to sort one column and accidentally save it, you may not be able to return to the sheets original state but if the first column is numbered then there is no problem.
Making a Sequential List of Numbers in a Column
The simple method for a few cells:
1) Enter the hashtag # into cell A1, then press return.
2) Enter the first number (“1”) into that cell, press return, then click on that cell, so it has the blue outline.
3) Click on the little black blob in the lower right corner of the outline, hold and drag down. You will see a tooltip appear with first “2”, then “3”… counting up as you drag the outline to cover more cells.
After dragging down for a couple of cells
4) Type Ctrl+Shift+Down (arrow); many cells are selected (black). The rest of the column is highlighted.
5) Menu: Edit > Repeat Fill. The whole column is now numbered.
Now paste the information you want starting in the next column to the heading #
Scroll down to the end of the information you have pasted and go to the first cell in the (#) empty row, to delete the unwanted numbers
Type Ctrl+Shift+Down (arrow); many cells are selected (blue). The rest of the column is highlighted.
Delete the highlighted cells and save your work.
I’m gathering a few autosomal tests for husband’s family. One for him, an aunt on his father’s side and an uncle on his mother’s side. Sadly, his parents are no longer with us. Anyway, I’ve been searching your blogs and found several articles on using spreadsheets for tracking but I’m still confused as to how many spreadsheets are needed and which sheets should be tracking what. I saw that you mentioned a link for more information on using spreadsheets but it was more about basic information on how to use them more than specific use for DNA tracking. I understood that you like to keep everything in one workbook but is it really just one worksheet to track matches, contacts and segments?
Judy –
It is up to you as to how to use your spreadsheets. Personally I like one spreadsheet for contacts and then one for each person for their matching segments.
Perhaps this post would be of more interest to you:
https://blog.kittycooper.com/2016/09/taking-it-to-the-next-level-dna-spreadsheets/
All my spreadsheet articles are listed under this tag:
https://blog.kittycooper.com/tag/dna-spreadsheet/
Many people like to use a product called genomemate to organize their matches. Leah Larkin, the DNA geek has a number of blogs about that.