The current technology for personal genome testing cannot tell you which of the two chromosomes, maternal or paternal, in a pair that an allele comes from. It can tell you that there is an AG at a specific position and a CT at the next position but not whether the A came from your mother or your father. This leads to much confusion about DNA segment matching.

Kitty and Shipley; siblings sharing 47% of their DNA
The matches that these testing companies find are for stretches of DNA that are half identical regions (HIRs). This is due to the fact that a relative who shares a DNA segment from a common ancestor with you will match you along the chromosome you got from the parent who is descended from that ancestor. Thus your new relative will match you for half the alleles in those positions. Only a sibling will share fully identical regions of DNA. Click here for a page that has a picture of the DNA I share with my brother Shipley.
For example, if my Dad gave me AAAAAAAAAAA and my Mom gave me CCCCCCCCCCC then I would seem to match absolutely everyone on that segment because every position has both an A and a C. So an ACACCAACCAC or a CCAACCCACA looks like a match, but only those with an AAAAAAAAAAA or a CCCCCCCCCC would be real matches. This is simplistic and the segment runs used for matching are much longer than this to try to avoid that sort of false matching. Also note than when your testing company shows an AC it is really an AT and a CG but just one of the known pairing is shown for brevity.
The term for a real match is IBD, which is an abbreviation for Identical By Descent. The term IBS means Identical by State which would apply to any false match. So in our example, the CCAACCCACAA match would be considered IBS.
However IBS is used interchangeably for false matches and matches that might be IBD. In other words, this term is used for all matches not proven to be IBD. So IBS is also used for matches that are from so long ago that we are unlikely to find the ancestor. I find this confusing. We had a discussion in one of the facebook groups about genetic genealogy where we came up with a new term, IBC, for identical by chance, to be used for matches that are known not to be real. In other words matches that are proven to be a mix of alleles from the chromosomes from each parent.
You may ask how a match can be proven to be IBC. Well if both your parents are tested, you can prove this by seeing that you have a match that neither parent has. If all three kits are uploaded to GEDmatch you can look at this in more detail by lowering thresholds.
Another way to prove an IBC match is when you have a number of people who match you on a segment but none of them match each other there. Then it is a false match like our example above. You can compare people to each other at GEDmatch or at 23andme if you are sharing with them. At family tree DNA you have to get one of them to check the match with the other in order to see if they match each other at a specific location. The ICW function cannot tell you where they match.
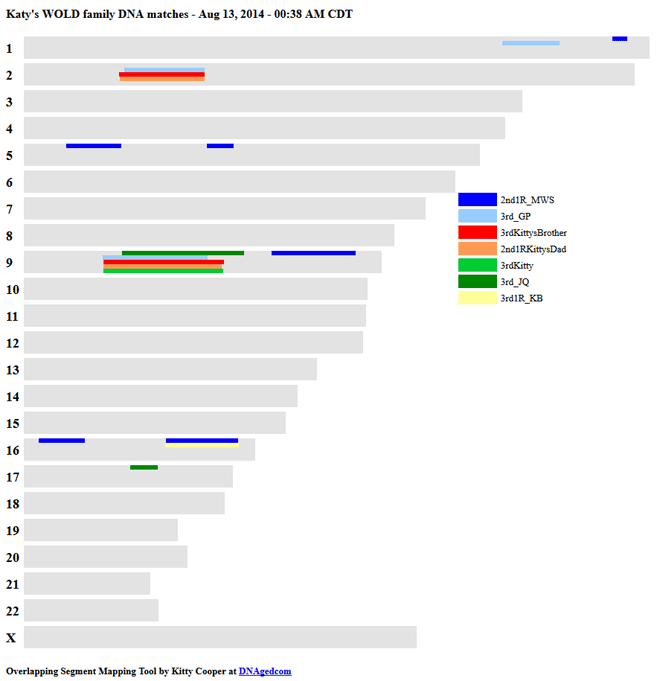
My known third cousin triangulating with other family members
When we have a DNA segment that matches another person we cannot be sure that it is a real match unless it is also a match to a third person who matches both of us at that spot. This is called triangulation. Having a parent or child tested can also help a great deal with finding IBD matches. When my Dad and I or my Dad and my brother have the same match at the same location, I can be confident it is IBD since it is phased. Parent-child phasing occurs when my Dad and I both match a third person at the same spot. I know that for us it is a true match since they are matching DNA I got from my Dad. Often the match will be a little smaller when passed along to us or larger due to fuzzy boundaries.
When only Dad has a match, I try comparing to various cousins to see if they have that match too, in order to confirm that it is IBD. I have found that there are certain locations where he has many IBC matches. Comparing notes to others, I find that these spots vary from person to person.
Additional things to be aware of in segment matching. DNA tends to stay together in chunks, thus the larger the segment match, the more recent the common ancestor (CA) may be. More than one matching segment of at least 8cM is usually indicative of a close relative (4th cousin or better) unless there is more than one common ancestor or you are both from an endogamous group like Mennonites, Polynesians, or Ashkenazi Jews.
John Walden has done some statistical analysis of the sizes of segments that are likely to be IBD versus IBC, summarized at this link on the ISOGG wiki. His results show that in most population groups, segments of 10cM or larger are almost always IBD, 8-10cM segments are good about half the time, 6-8cM more likely IBC, and smaller segments more and more likely to be IBC.
So I hope this clarifies DNA segment matching and the terms IBD and IBS and I really hope some of you start to use the term IBC as well.
It’s confusing enough calling them IBD and IBS and a third term IBC which sounds very much the same only compounds this. We might even say that the three “IB” are IBS with one another.
Since, as you acknowledge, the IBS (without the IBC component removed) is a legacy from pre-genealogical time but still from out ancestors, I prefer to call these “splinters.” Which is what they are – small bits left over from larger, more useful segments.
Sorry – that should be “with the IBC component removed”
What I am looking for is a good term for a completely false match, where bits from each parent appear to make a match but non-triangulation proves that they are not even splinters. That is what Identical By Chance, aka IBC, was designed to indicate … perhaps I will have to stick to false match
Ciao sono kevin ho un gruppodi persone che ho una triangolazione loro sarebbero figli di cugini di 4 e due di 5 cugini per myheritage.segmenti che triangolano stesso chromosome stessa posizione .loro hanno gruppi genetici dei paesi balcanici io sono sud iraly puglia che vuol dire?
Normally a group that triangulates shares a common ancestor. However if this triangulation is at MyHeritage then possibly it is not correct if you uploaded from elsewhere, as they infer some results. How large is the shared segment? Less than 10 easily can be false. Even less than 20.
Also ethnicity results for Europe should not be taken too seriously. We are all interrelated if you go back far enough.
Thanks for this! And everytime when I tried to explain what IBS was, I’d use the term “just by chance”, and I remember awhile after that when that discussion in the ISOGG FB page these other terms were brought up, as well as I was told how in my situation, there is both IBD & IBS, which is what made it confusing.
I do like IBC though.
Ok grazie io ho un match il segmento 12,5cM mentre con mia madre sono due segmenti il piu grande 8,1cM con questo match ma questi match ha testato I suoi genitori ma ha detto che mia madre non corrisponde ha nessuno dei suoi genitori.
Then if his parents do not match, it is IBC, in other words a match by chance with bits from each parent
Ciao io ho un gruppo di 12Marche a che sono tutti d’accordo sul cromosoma 16 abbiamo una triangolazione e corrispondano anche tra di loro.poi ho due match sempre di questo gruppo che hanno sul cromosoma 4 si sovrappongono ma mhyeritage non segnala il segmento triangolari anche se sono segmenti un po piccoli .però sul canale 16 questi march sono d’accordo con me tra di loro tutti sul 16 perché tra di loro qualcuno tra loro sono mezzi ho cugini di 1grado e poi tra loro sono anche cugini un po istantanea il 3 4 5 grafo anche io sono tra il 4 e 5 grado cosi dice mhyeritage.ma queste persone hanno tutti d’accordo tra di loro perché dai risultati e gruppi genetici che ho visto hanno tutti in comune tra loro asia meridionale e anche altre etnie qualcuno etnie che ho io per esempio greco e suscitato e medio Oriente.
To me, there are only two kinds of “shared” segments (HIRs) that are reported by algorithms:
1. Those with ACGTs that match an ancestor – they match (are HIR) because they came from an ancestor – IBD.
2. Those that are made up as various maternal and paternal ACGTs – they only match because an algorithm assembled them – you could call them IBC.
For genealogy, these are the primary options.
There may be shared segments from distant ancestors. How distant? What is the cutoff? Even with a distant group of segments forming a Triangulated Group, this TG is part of your chromosome map. You have DNA at that location. One parent had DNA at that location. One grandparent did, too. Probably some cousin, but maybe not. But it’s on your map. And some Matches share that segment. I think it is very confusing to try to invent a new category – a new term – for such segments. It’s all a matter of degree, which is very hard to define. Particularly when some closer ancestor covers that location.
Personally I like the term NIBD, or NBD: Not By Descent using 3 letters.
No matter what we call it, we have the additional issue of shared segments that have sub segments (which actually every IBD segment does). An aunt or uncle or first cousin shares some large segments with us. These large segments are made up of smaller segments, until you get down to your threshold….
Love that you wrote this. I occasionally get requests from folks wanting help tracking down a common ancestor where our match is under 4 cM. It’s hard to explain to them why I’m not interested in working on such small matches.
And that’s a great photo of you and Shipley.
Jim I like NBD too, that is a nice one. I really want a term that will make it clear that there is no match at all, just random bits from each parent being matched up incorrectly. Many people use the term IBS for segments that are actually IBD but just too far back to find so I was looking for a new term that was less confusing.
Thanks Kalani – notice that I mentioned Polynesians 🙂
And thanks Jeri, glad to help out
Thank you for the compliment Israel. The photo is from 2000 and I like that you can see the similarity between us which is why I used it 🙂
Thanks for a reasonably simple explanation.
Paddy Waldron pointed out on Facebook that in addition to siblings, double first cousins and other doubly related folk can share some FIRs (fully identical regions of DNA) as opposed to HIRs and gave a link to his far deeper discussion of false matching (advanced users only!) http://www.pwaldron.info/DNA/significance.html
I liked your IBC until Jim said NBD – that really says it. However, since I have neither parent’s results, I will have to play with my sister’s and her two sons to see what I can find.
The other K
I am searching for matches for unknown father. I’ve tested myself, children, and many cousins. Is there any significance in that of 1500 matches on gedmatch my son only has one x match -and a significant match (28Cm) at that. This x match also triangulates with me – completely- and with my daughter but with a much smaller segment. We also have triangulated matches on other chromosomes with this cousin and this cousin match does not match any of my other cousins . Could this x match signify the x that I received from my father (from his mother) and passed on to my children?
Deborah –
If this new DNA cousin does not match any of your maternal side cousins then they could well be from your unknown Dad’s side and yes that X could be from him.
Have you checked out the methodology at the DNAadoption site? They also have a yahoo mailing list and there is one for unknown fathers as well.
if some one is 18 segments is that really a close relative? im new and confused
Rodney –
How many segments greater than 7cM and the total cM for those segments? See http://www.isogg.org/wiki/Autosomal_DNA_statistics#Statistics_categorized_by_genealogical_relationship
and join the DNA-newbie yahoo group or the facebook one as I am travelling and not very available for answering questions
Hi-
I have a confirmed through paper trail 7th cousin 1x removed and we share about 9 cM. Is this IBD because we have a confirmed relationship?
hi Jake –
Very likely that this DNA is IBD and from your common ancestor but it is not for sure until you have it triangulating with another relative descended on the same line.
I talked a few close cousins into testing to increase my triangulation chances…
Here is my article on triangulation – http://blog.kittycooper.com/2015/02/triangulation-proving-a-common-ancestor/
Thank you! Unfortunately, I tested at Ancestry, and the matches on the line aren’t on GEDmatch.
Jake try sending them a link to this article –
http://blog.kittycooper.com/2015/09/please-upload-your-ancestry-raw-data-to-a-site-with-a-chromosome-browser/
Will do.
Want a Laugh? IBS, IBD, IBC
I saw the title and wondered if I might find my wife some help with her IBS (Irritable Bowel Syndrome). Thought I might be able to find out whether to blame her father or her mother.
Glad I read further! LOL All these initials are used for the the bowel as well: IBS (above); IBD – Irritable Bowel Disease; IBC – Irritable Bowel (Constipation).
Anyway. A good laugh.
Right now the main stream of thought is that 7cM’s or possibly as low as 5cM matches should be used to confirm IBD cousins. The math for triangulations hasn’t been developed as far as I can tell. Is this true? They simply know that triangulations are a significant means of confirming ancestry that also has historical documentation.
I believe that a brilliant mathematician will be able to improve our statistical analysis of IBD’s vs. IBS’s via the following patterns.
1. Ancestry has stated that mathematically out of 30 cousins found descending from the same MCRA, there is only a 4% chance of finding a triangulation between them. (Therefore, statistically shouldn’t each triangulation increase the likelihood that any cM’s in common between 3 cousins descended from the same ancestor verify IBD’s vs. IBS’s?)
2. If someone did a study on how many times even persons with the same historical ancestors in common have any cM’s in common, shouldn’t that too refine the chances that IBS’s are actually IBD’s?
3. From Blaine Bettinger’s chart that many of us have seen, the following close relationships can have as little as 0 cM’s in common: 2C1R, 2C2R, 3C, 3C1R, 3C2R. Again, is that a factor that might be able to be used to refine into this analysis as compared to any cM’s in common back in time?
Obviously, we are still in the infancy of this science. I have great hopes that the future will help us do improved analyses to distinguish between IBD’s and IBS/IBC’s. What do you think?
I appreciate your desire to simplify, to substitute more intuitive terms, and I do see IBC used a little. NBD is a simpler idea, but still a new term too. I think the simplest though, and therefore the most likely to catch on, is to drop all terms but IBD, and make the question ‘IBD’ or ‘not IBD’ (to almost quote Hamlet).
Your article is well written, a good persuasion for the use of IBC. And if it sticks, I’ll use IBC. But I do feel that ‘not IBD’ is simpler, one less term to remember.
Rob, frankly in my talks I use the term false matches and try to avoid IBD or any of the others. Too much jargon. Your suggestion of not IBD is just fine.
If there are two related cousins that share segments separately with a thrid person, one is above 20cM the other falls into the <5cM category on each segment, and the three only share one segment together, how does that show os IBD or IBS? I am trying to find my grandson's biological family. One cousin is considered a first to third cousin and the other is considered as a 2-4.
Sandra –
Cousin s do not have to overlap and matches of less than 5xM are usually false. These cousins of your grandson could be from different lines.
Read this for more help
http://blog.kittycooper.com/dna-basics/help-for-adoptees/
Hello, Kitty. My mom is an adoptee in Brazil. I was only able to confirm Amerindian descent by a 5-6% of my genetic makeup (otherwise European) through mtDNA haplogroup, but there are a ton of gaps on her side still. What has been sparking my curiosity currently is my presumed Scandinavian biological great-grandmother. I met her when I was 5, which was almost 30 years ago, my mom has no info on her, and found a document containing only her first name. Her surname was illegible. The thing is, all of my matches are distant. My closest is likely a 5th cousin on my dad’s Euro-born side who lives in Australia (Brazilians aren’t big on DNA testing, especially when vendors are hard to reach here). So I have to work with that, as I haven’t been able to have my parents tested yet.
The deal is: I have, on FTDNA and GEDMATCH, a ton of Swedish matches (no pun intended). Aside from the 20-15 cM Brazilian ones I have been trying to find a link with, they are the majority… in fact a lot more than my actual known ancestry. However, the cM range is between 8-11 cM for the longest segment on chromosome 9 (same region) between us. The same goes for my American matches with unknown ancestry. Could this be a case of IBS in a population or is it more likely it’s IBD? Note: I have not confirmed Swedish ancestry at all on my paper trail. I did get a 12% Scandinavian on MyOrigins 2.0 (reducing a bit my massive amount of West-Central Euro and eliminating Eastern Euro), and exclusively Swedish matches (except for a few Norwegians and Finns sith recent Swedish ancestry).
Could I please have your insight on this?
Thanks in advance. I’m a great fan of yours and Roberta Estes’s.
Kind regards.
Ana –
Are you tested anywhere else? FtDNA is probably best for Brazilian DNA but I do not know that for sure. It has the smallest total autosomal database. Is your mother tested? Your father? Any siblings? All those tests could help sort out which matches are real and maternal side.
If you have some 30+ matches all on the same smallish segment then yes it is likley population IBS. 11cM is usually IBD but one segment matches can go far back. I have one of those too, also 11cM on chr 9, which matches many Russians (no russian ancestors here but perhaps one of my Norwegians wandered in that direction …)
Be sure to upload to MyHeritage for more matches and DNA.land (less likely for matches but helps science and is fun). 23andme has a fair number of foreigners so perhaps test there too.
More and more people are testing so patience may be best.
Thanks for the praise!
Kitty
Hello Kitty,
I have a shared matched with a DNA relative that is a predicted 3rd cousin. We have established that we are descended separately through a brother and sister–he through the brother and me through the sister. I understand that the segment has to be attributed to one of the parents, however do you know if that single segment of DNA can contain remnants of both parents or is it impossible for that to occur? Also, if the segment is attributed to one parent, can that segment be further disseminated to reveal remnants from earlier ancestors and if not why? I am an armchair genealogist and by no means understand everything DNA. Just curious.
Thank you.
A, wood –
Segments tend to travel in chunks so it is most probable that the segment you share is from one parent or the other but not both. However in our maps we tend to assign it to the couple until we know more.
It is in theory possible for it to be a chunk from each parent that happen to be next to each other that both of you got, but extremely unlikely. I have never seen this but then often we do not know which person in the couple it is from until we get another match there from a further back ancestor.
Hello Kitty,
Something that I haven’t seen on any blogs is considering the number of SNPs in a segment to help determine if it is an IBD or IBC match. I’ve noticed on GEDmatch that as a rule of thumb the number of SNPs per cM in a segment equal around 100 per cM. However, sometimes I find segments that run between 200 to 300 SNPs per cM. I’ve paid close attention to that for a few years now and found that even when segments are less than 6 cM, if they are in the 200+ range per cM they tend to be real matches. I have done a lot of testing on my Y DNA and have found quite distant cousins whom I can verify through Y DNA testing as being from the same line. One of these is a 7th cousin (cousin A) who wasn’t a match on Ancestry. However, he had another much closer cousin (cousin B) through his paternal line that was over a 15 cM match to me. Cousin B didn’t have any other known lines that he could have matched me through. Actually, I found cousin A by contacting cousin B who introduced me to cousin A because we shared the same surname. Cousin A’s Harp’s lived in very close proximity to mine throughout the late 18th through mid 20th centuries. But, we couldn’t find the common ancestor. Cousin A was also on GEDmatch so I compared myself to him and we didn’t match. So, playing around with GEDmatch I lowered the minimum match criteria to 3 cM with 500 SNPs. Up popped 5 tiny matching segments on 4 chromosomes all about 3.5 cM with over 200 SNPs per cM. I know the prevailing wisdom is that anything less than 7 cM at the least isn’t very likely to be IBD, but with this high amount of SNPs per cM on every single tiny segment, I was intrigued to continue working on this relationship. I found a few other matches that cousin A and I both matched, but on different chromosomes though they were decent matches to each of us and they all shared what appeared to be a related paternal line to cousin A and me. So, I tested cousin A for one of my Y SNPs at YSEQ and he was positive for it. My Y DNA haplogroup is very rare so this was even more significant. We recently got the results for a Big Y test on cousin A and he is definitely of my haplogroup and has about the right number of new variants to be a 7th cousin. In the process we discovered that our Harps used to be Herbs (pronounced “Hairp” in German). The name had been spelled differently in predominantly English areas of Pennsylvania and had become Harp through being misunderstood by the people writing the records of the day. So, we now know who our common ancestor was and he was the immigrant, born in 1699 in Germany and immigrated in 1734, for our paternal line. I’ve had a similar experience with a 4th cousin who only showed a high SNP count on tiny segments and otherwise wasn’t an autosomal DNA match. I’m not saying that a high SNP count on all tiny segments will always be IBD, but I believe that they are worth pursuing and will have a better chance of being IBD.
There is no direct relationship between SNPs and centimorgans because the ends of your chromosomes will recombine more readily in shorter strands so there are more cMS to less SNPs than at the center. My rule of thumb is a low cM count with more than 1000 SNPs is worthwhile.
Of course there can be valid small segments like your 3cM ones BUT for most matches they are not worth pursuing as the majority are noise. There is also the distinct possibility that there is another inheritance path for them.
I am delighted for your success with them but I would not want to encourage this approach unless it is very directed at a specific line like yours is.
Could a match be IBC even if it is in a triangulation?
Aunt (A) and Niece (N) triangulate with T by 10.1cM. I’ve compared A and N to several other close relatives and determined that they share this segment on the same allele.
A and N also triangulate with two other people C and M, 10.9cM, same segment, same allele.
But T matches neither C nor M, at that same spot. The only way I can figure this is if A and N have inherited the exact same segment, and T only matches them IBC. Could I also say that since A&N are so closely related, they are not valid as two points in a triangulation anyway?
Thank you for explaining all this in plain english!
Looks like you have it figured out! T is an IBC match.
A and N are fine for two points on the triangle. Only the word allele is misused in your analysis. An allele is a single point not a stretch of a chromosome. So “they share this segment on the same chromosome” is likely what you want to be saying.
An aunt and niece will share one family line so their matches will be from the same side in the paired chromosomes,
Hello Kitty,
Thanks for the great article. I have two remaining questions. Quote: “At family tree DNA you have to get one of them to check the match with the other in order to see if they match each other at a specific location. The ICW function cannot tell you where they match.”
At the time of writing the Chromosome Browser wasn’t available at FTDNA? Otherwise I’d need an explanation why I have to get the matches to check each other.
My second question: in the case of both parents tested and phased kits at GedMatch to what values can I lower cM and SNP thresholds? I’ve read somewhere values of 4-5 cM and 500 SNPs. Any literature on that so far?
Thanks again,
Martin
Martin
To get the chromosome browser at family tree DNA you have to pay the $19 to unlock the additional tools if your kit there is an autosomal transfer. Otherwise family finder kits always have one.
Just because your kits are phased does not mean the other kit is phased so no I do not lower thresholds except for known relatives. Then I use 6cM and 500 SNPs but that has no science behind it, just my experience
Kitty,
I originally tested at FTDNA, so I didn’t think of external uploads. And thanks for your view on threshold levels, caution still seems to be best practice.
Kitty,
Any advance or opinion on much larger matching segments that ought to be IBD but may be IBC? About half my atDNA projects consist of large groups of single segment matches (in the 10cM-30cM range) that appear not be related within a reasonable genealogical timeframe (at least no-one has found MRCAs). They can best described as long-surviving segments that have not undergone the breakdown through the generations as one may expect. As a consequence, GD (genetic distance) can be severely mis-estimated by 3 or more generations. Work has indicated that these originate from a time period pre-1700’s. I haven’t seen much about them, as the presumption these are markers that ought to indicate.
The warning signs are large numbers of single segment matches (for example nearly 100 of my top 4000 matches on Ancestry share one of these markers) with no obvious MRCAs or supporting markers. Because they have older origins they may not have an obvious geographical focus, say for example my matches in the US (I have British ancestry) whose family all arrived prior to 1730, or those Norwegians I share a marker with (and I have no obvious Scandinavian family in my 10-generation tree).
Mark –
I tend to ignore single segment matches as groups like the one you report are usually “Pile ups” from too far back to find the relationship. My Dad and I have a 13-18cM one on chromosome 9 with over 50 matches, mainly of Russian descent (Dad is almost 100% Norwegian).
See the explanations here and the links quoted
https://blog.kittycooper.com/dna-basics/newbie-faq/#__RefHeading__1663_1036851304
Hi! I’ve seen your name on Wikitree. Can you explain why I fully match (in green on GedMatch) in long segments a family on first part of chromosome six, but GedMatch calls it no match? I half match some up to 120 cMs and full match some up to 60cMs. According to GedMatch, some are real cousins from 6-10 generations to common ancestor. I learned this by triangulating other segments GedMatch listed. But this long full-match segments that are called “no match” really bother me. It is in this area of Chromosome Six that my immediate family has health issues, some serious. I asked GedMatch twice to explain this to me and they just sent me their “facts” sheet.This would be so much easier if I could load a screenshot. I understand short random matching, but segments this length don’t feel random to me, and I question GedMatch’s technology because I ran my kit against itself and in this Chrom. 6 region, they called I had low confidence in a match! Is their technology flawed or what? Thanks!
Deborah –
The short arm of chromosome 6 has the HLA area, where there are many genes important for the immune system. Since these are fairly standard that area often includes much false matching.
I will send you an email and gladly take a look at this for you.
I want to thank you so much, Kitty! This is the clearest explanation that I have read so far and gives me hope to be able to break down a brick wall.
Kevin no io ho testato su myheritage poi quando ho fatto aggiornamento mi sono cominciati ha uscire questi match e ho traiangolazione sul canale 16.ho fatto testare mia madre ma ha lei non risultano io ho il mio test ma non quello di mio padre ho solo il mio pero escono match che corrispondono ha qualcino di questi match che ho io forse loro sono impare da qualche altra linea.I srgmenti piu grandi che triangolano sono faccio uno co tro due ha volte e 9cM ha volte e 8,6cM pou 7,5cM pou quando su myheritage ha aggiungo 7 persone il srgmento triangolato dicenta 7,1cM.poi ho inzio e fine con alcuni di questi match e poi chiudo ho altro tg sempre sul 16stessa allineamento del primo tg ma due tg separati stesso cromosome e alcuni del primo tg hanno stessi numeri iniziali e fine sia con me che con altro tg ma sono separati che significa?ho il mio test mia madre non corrisponde ha loro.
Well Kevin, the two possibilities are
1) there is a common ancestor on your father’s side with these matches
2) or … because these matches are small (less than 10 cM) they could all be false matches, especially if that area of your chr 16 is heterozygous. I would recommend looking at the actual data for that section of chr 16.
Here is my discussion of false matches
https://blog.kittycooper.com/2014/10/when-is-a-dna-segment-match-a-real-match-ibd-or-ibs-or-ibc/#more-2309
Here is more about heterozygosity
https://en.wikipedia.org/wiki/Zygosity