The genealogy airwaves have been burning with discussions about losing DNA matches with less than 8 cM shared at Ancestry. For my own family there is no loss, but I feel for those who were impacted. If the site responds faster and better then it was worth it in my opinion. Who can look through some 25,000 matches anyway?
To see how many matches you have left click on the Shared DNA in the list of filters as shown below with my added red arrow.
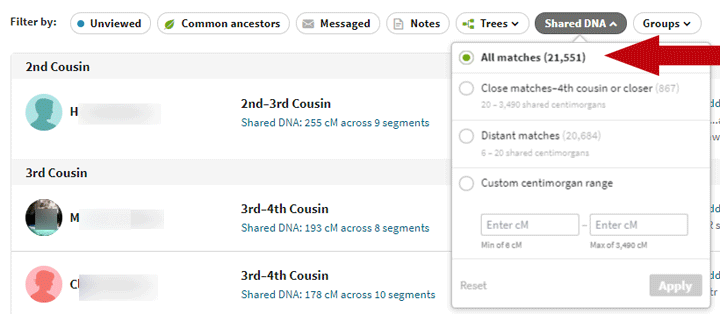
Personally I happened to save 72 of my small matches because I had made a note or grouped them with a colored dot. These included 35 with common ancestors who were grouped; I always group matches with shared ancestors. Whether the shared DNA is actually from those common ancestors is unclear. The half of them from my endogamous Norwegian area may well not be, but the others are probably good.
I liked the suggestion a reader made in a comment on another post that suggested Ancestry look for common ancestors and if found, keep these small matches. I wonder how hard that would be to do for new matches.
To see my remaining small matches I tried entering a minimum size of 6 and a maximum of 8 but that did not work at all well since all the matches of 8 plus a fraction showed up. So I had to use 7 for the high number as shown below with my added red arrow.
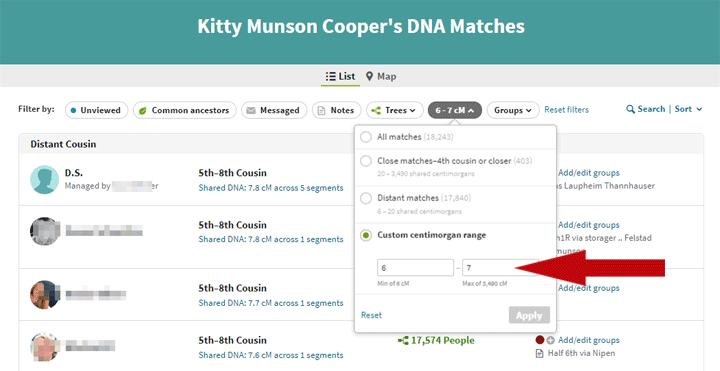
I had collected some statistics for me, my brother, and my tested cousins before the change and added the new numbers just now to look at the differences.
I indicate the possible endogamy, either colonial American or Jewish. All my cousins except M have some minor Norwegian endogamy as well. Here are our numbers; the total from 20 Aug 2020 and the total after from 31 Aug 2020.
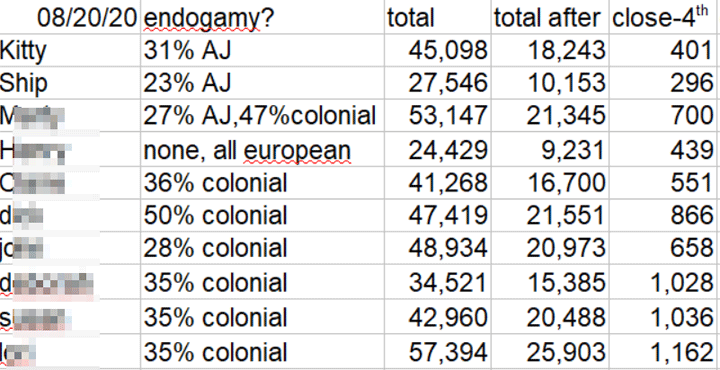
UPDATE: My 100% Jewish husband still has a riduculously large number of matches at 102, 315. Apparently I did not make a note of the number before the change over. All his matches of less than 8 cM are gone.
I want to thank my many cousins who have not only tested at Ancestry at my request, but have then shared their results with me so I can work on my family projects. Thank you all so much!
I also like the suggestion that Ancestry continue to look for common matches with ThruLines in the 6-7.99 cM range. I have been very pleased with the results from ThruLines and I would like to get these small segment results from new test takers. In addition, I expect ThruLines to continue to improve, and also to hopefully be extended from 8 generations to 9 or 10.
However, regarding the site responsiveness issue, the problems I have had seem to correlate with replacement of the old page numbering system for match display with the new one in which all matches of interest are on one, sometimes very long, page. The new system does work well with a very long page. My guess is that response problems in general would be substantially alleviated if the old page numbering system for matches could be restored.
I tried to save the ones in my thrulines but ran out of time. Was surprised to find one that is a younger descendant of cousins I personally have known my entire life. I already expected to lose a few descendants of another great grandmother. While she is not a distant ancestor to me, she is 2 or maybe even 3 generations farther back from some younger test takers. And especially since they are half cousins from my great grandmother’s first marriage, many of my matches with them involve quite small segments. Their match to me could have helped them, a lot. For my own objectives, while I realize small segments are sometimes unhelpful, I found those large clusters of small segments surrounding a 4th or 5th GGrparent—or the lack of a such clusters—to be helpful hints along side paper trails which are sketchy in that time period.
I tagged as many matches as I could that had trees, many of them were thruline matches. Most of my brick walls are in the 1700’s and these small matches were helpful at times to point me in a direction I hadn’t looked in before.
It did appear that my Thrulines were cleaned up during the recent changes, for that I’m grateful.
I have access to six DNA tests at Ancestry that I manage for myself, a sister, a daughter, an uncle, an ex-, and a friend. As expected, the overall average of total matches dropped by about 44% (comparing yesterday to last January when I last noted the numbers).
Surprisingly though, in every case the number of what Ancestry deems “Close Matches” (4th cousin and closer) went up by about 7%. At first I thought this may have just been due to the 8 months growth of the total data pool. But then I wondered if it might be attributed to better/more accurate processing with almost half of the processing load being reduced.
Any thoughts/explanations on that, and do you suspect this level of close match increase is the rule rather than a few exceptions?
Steve –
I would expect that the increaase in “Close Matches” is in fact due to the incredible growth of the data pool.
I agree with the comment about the paving of matches. I think that a return to the previous paying of matches where you could click through pages instead of one long page would solve many problems. I also found it much easier to work with. Scrolling through a long list to find someone can take significant time. Previously, you could just jump to a page.
Hi, Kitty. My 6-8CM matches are still there for now. I just printed out 29 pages(!) of the ones with Common Ancestors. There are hundreds more that don’t have Common Ancestors listed but still might be helpful. This change is devastating to the many, many descendants of enslaved people. As you know, I’ve been working with my cousins who descend from those who were enslaved by my ancestors. I have learned so much on this journey about the paucity of written documentation for those tracing Black ancestors in the U.S. Those smaller CM matches often provide clues to possible relationships that can break down the brick wall of 1870.
I have been teasing out strands of my family that go back to the 1600s in the US, and those <9CM matches have been critical to my search. I'm really distressed that Ancestry.com has followed through with this decision after all the feedback from those researching Black ancestors.
Understanding that low CM matches can turn out to be false matches is a part of the challenge, along with duplicate names, errors on censuses, and family stories that turn out to be wrong. I wish Ancestry had emphasized that point rather than taking away tools that help us find clues to those distant connections. For those who don't want to see all those smaller matches, it's easy to set the filters to ignore them.
I assume that Ancestry.com has the wherewithal to find other ways to make the search engines faster and more accurate.
Thanks for listening, my friend, and for keeping us informed.
My dear Mimi, if you would like to write up a case where these small segments actually helped I would be happy to publish it as a guest blog.
The way I see it is that since Ancestry has no tools for actually examining the small segments to see if they have a clear ethnicity or if they triangulate with each other and thus can be assigned to specific ancestor, I find it hard to see how they are genuinely useful.
Note that at GEDmatch you can see who matches whom on a specific segment so that is where I do most serious research. At 23andme you can look at the ethnicity of a specific segment, which can also be quite helpful. MyHeritage includes automated triangulations and filtering matches by ethnicity or country so has many better tools than Ancestry.
Thanks, Kitty. Someday I may take you up on your generous offer. In the meantime, here’s a link to an article by Roberta Estes about how those small segments are used in searching for clues to the histories of those who were enslaved. She explains it far better than I ever could. https://dna-explained.com/2020/07/19/plea-to-ancestry-rethink-match-purge-due-to-deleterious-effect-on-african-american-genealogists/
I should have proof read the comments prior to hitting the ‘Post Comment” button. I hope the Blackstone Corporation is satisfied with its work. I lost 32,000 6 and 7 cM matches. Common ‘knowledge’ flying around was that only half of them were bad. Well if the other half was good we’re talking about 16,000 matches. The baby was thrown out with the bath water. We were told this would improve accuracy. How by getting rid of the bad matches at the expense of the good ones? It was also supposed to improve accuracy. The accuracy of what was left improved on a percentage basis. But how did it improve the remaining matches? That logic is similar to that of, if anyone would say this, “we have so many cases of Covid-19 because we’re testing so much. If we tested less we’d have fewer cases”.
I fixed it for you by deleting the previous comment. To me the problem is that Ancestry has no tools for actually examining the small segments to see if they triangulate or have a specific ethnicity so there is no way to know if a small segment match is a true one. Therefore why waste your time on them?
As I see it, the issue of small segment (ss) DNA matches at Ancestry is best placed in context, the context being the potential availability of shared matches and of trees, sometimes ThruLines enhanced, (as well as the absence of a chromosome browser). This information can help identify common ancestors for other matches with longer segments that are certainly true matches.
This general approach can even be successfully used with apparently invalid matches, as shown with the following example. One pair of my 4x great-grandparents has 157 ThruLines matches, of which 39 are in the 6-7.99 cM range. Of these, 38 have multiple shared matches (20 cM cut-off) with other members from the same group or cluster. About half of these 38 matches are expected to be technically invalid, yet they still share matches at over 20 cM with other members from the same group or cluster. One mechanism by which this indirect detection of true matches using an apparently invalid match could occur is if more than one segment or chromosome was involved.
The above is an example of how one might use a shared match from a ss match to help identify an unknown cluster or common ancestor. Even a single shared match with a common ancestor identified might help in an identification of an unknown match with a long DNA segment.
I feel that the conclusion one reaches about the ss DNA match issue depends considerably on how it is framed. An advocate for proof beyond a reasonable doubt (an assignment) could reach a different conclusion from someone who accepts genealogically useful information in the absence of a chromosome browser.
I can hardly find matches at 50cM so dumping the 8 cM or less makes perfect sense to me. There may be countries with GGGreats or more Gs on record, but Ireland certainly isn’t one, at least for my Catholics.
It’s all very well them saying that the tiny matches are far away.
But zero shared DNA begins at 3C. And I have several 3C matches with only 6cM. And they are fairly local – just a short drive from where I grew up or where I live now. One was crucial for re-discovering a branch that had disappeared from records. A 4C link in that range was to a branch that unsuspectedly went to USA while the rest of the family came to Australia.
Meanwhile I am flooded with 20-30cM matches of Early Colonial US matches, with CAs around 1600. They might be valuable if the match had researched even the English county they came from, but as is they are just spam. And by far my two biggest clusters.
In my view this was a poor decision as I am doing a DNA matching project to find commonalities amongst my ancestral families from County Kerry Ireland. The project involves descendants of about eight different Devine families from Kerry. I did the first pull of data about 18 months ago and found that people who were descendants of other Devine families from Kerry who were matches have now disappeared. I am confident the initial match was valid as other descendants of the same Devine families remained matches. I have also found that people I know to be 2nd to 4th cousins of mine have small shared DNA so the strength of shared DNA is not singularly relevant. I get the reason but it is a detriment to someone who wants to undertake a complex analysis like I am doing. Everything with Ancestry seems to be tailored toward the simplistic, including the fact there is no way to download your DNA matches into a spreadsheet. This should be pretty basic programming yet my efforts to urge Ancestry to do this seem to have been ignored.
Dave,
This is just not ancestry’s focus. You really want to be looking at the segment data anyway for this type of project.. So get your distant cousins to upload to gedmatch, family tree DNA, and/or Myheritage… The first two have family/region project groups that can be set up