There are many new ways to make those beautiful cluster diagrams of how your DNA relatives are related to each other. Both MyHeritage and Gedmatch (tier 1) now have clustering tools (Thank you Evert-Jan Blom). These charts give you an easy way to see your family groupings and can help you figure out a new match since each cluster typically represents a common ancestral couple. Click here for my previous posts on clustering which is based on the Leeds method.

My Dads Clusters at Gedmatch GENESIS
The GEDmatch cluster diagram shown above includes the total cM each match shares with you as well as their name and kit number. Click on the “i” in a circle for a pop up box with the user information which includes an email address and whether a GEDmatch tree is linked to this kit. Any of the colored boxes on the graph can be clicked to open a window for a one to one comparison between those two people. Plus you can check the boxes in the select column for any number of matches and then submit them to the multi kit analysis using the orange “Submit to Multi Kit Analysis” button above the name column on the left. To get this clustering tool all you need is a Tier 1 membership and a kit number. It is listed at the bottom of the Tier 1 tools. Personally I like to raise the thresholds to a top 200 and a minimum of 20, but try the defaults first and see what is best for you.
One of the nice things about the cluster output from Genetic Affairs is that it lists all the cluster members in groups below the graph with the number of people in each tree (clickable) and any notes you made on the Ancestry profile. The MyHeritage version also has those cluster lists with your notes and the tree sizes; and of course they are clickable to the match (which may even have a theory of family relativity for you!) and the match’s tree. The down side is that you cannot select the parameters for the clustering yourself, they are preset. Possibly only power users care about that!
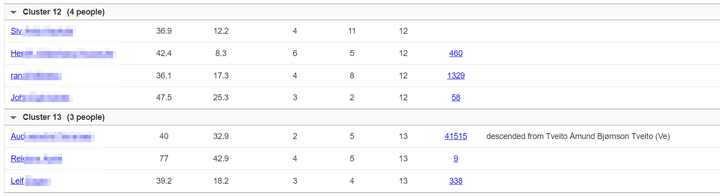
Extract from my list of matches in each cluster at MyHeritage
An exciting new feature for those looking for one unknown parent or grandparent is the ability to cluster just your starred Ancestry matches when using the clustering tool at Genetic Affairs. Click here for my previous post about that tool. There now is a checkbox on the page where you select your parameters for getting a cluster analysis.

Newat Genetic Affairs is the checkbox for only starred matches when starting a cluster analysis
It is a common practice to star (mark as favorites) the matches that seem to be from the family of an unknown parent or grandparent at Ancestry. Usually these are determined by looking at who matches or doesn’t match a close relative like a half sibling or else by eliminating matches from the known side. Sometimes you can use ethnicity. I am currently helping someone where the known side is Jewish and the unknown side is Italian and those are easy to separate.
My previous technique was to use GWorks from DNAgedcom and I still do that when clustering does not give me a fast solution. Of course their client tool now has clustering as well; click here for that post.
The DNAgedcom client program creates a match list CSV file which has a column for whether a match is starred or not so it is easy to separate the starred matches out by using a spreadsheet sort on that column. Then cut and paste those matches into their own spreadsheet. Next use my slicer tool to put the ancestry tree data for just those matches into a CSV in order to use GWorks – click here for that blog post.
However clustering is often a quicker approach when you can find the common surname and ancestor for the clusters of interest. Since you can click to the trees of the matches in a cluster; you can often spot the common ancestor easily.
A word of caution, clustering is not much help in endogamous communities. Here is an extract from a cluster graph from Genetic Affairs for a Lebanese American:
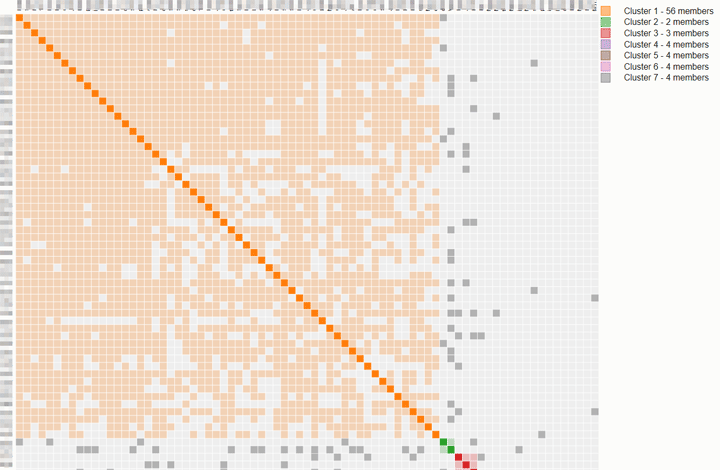
Clustering does not help when your ancestors were endogamous!
And here is my half jewish aunt at Genesis which is not very useful even with a lower limit of 50! There are no clusters on her non Jewish side as the only tester is a cousin we asked to test. Testing is just not popular in Germany yet.
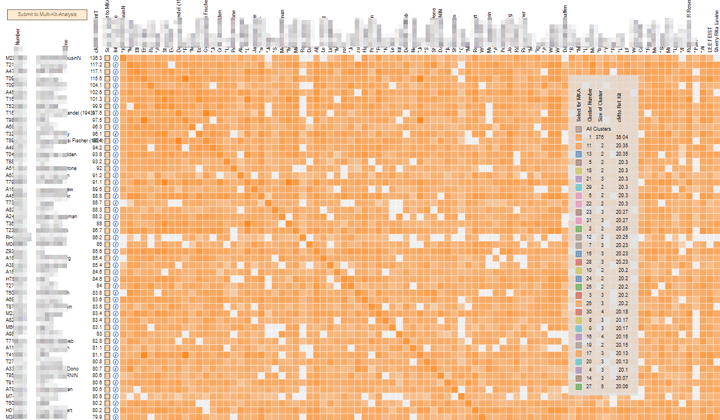
Curious what your 1/2 Jewish aunt’s results would look like if you increased the threshold significantly? Her lower limit (default?) looks similar to mine where there’s a huge major cluster & other clusters. Increasing it up to 100cM or maybe I had it at 200cM or so gave me 1 cluster with a lot of names in them still.
good thinking Kalani, at 100 lower limit there are only 5 matches and 2 clusters for my aunt but the real problem is that all Southern German Jews are related … often recently!
Thank you for demonstrating these clustering tools. It is good to have multiple ways to check out the data. Have you tried the DNA triangulation tools in Rootsfinder yet? Their cluster images are somewhat different but the way they can show ties between matches is nice. And you can play around with the various search limits to show closer matches, more matches or fewer matches.
Kitty, Good article. I have been getting notice of DNA matches from MYHeritage for people living in Germany and France.
Jay
Hi, I have been trying for some time to track down my paternal grandfather. My father 90, had for some time believed his father to be of the Jewish community in Tailoring in London. This was confirmed with DNA testing with myself and then him this year. All our close matches, being 2nd cousin, then 3rd are in America. I have used clustering and good old leg work. Looking at other peoples trees, messaging people.
Any other ideas people please.
Jo –
Jewish DNA is difficult because everyone matches everyone to some degree… this can make clustering useless unless you set the parameters high. 2nd-3rd cousins can actually be 5th cousins 4 times over so you need to look at the longest segment. See
https://blog.kittycooper.com/2021/03/more-on-ashkenazi-dna/
Upload your DNA to every site and if you can develop a theory then target test people whose DNA may narrow it down.
Also talk to anyone who may know the back story.