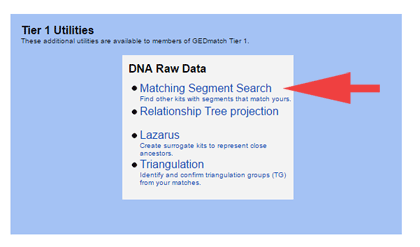
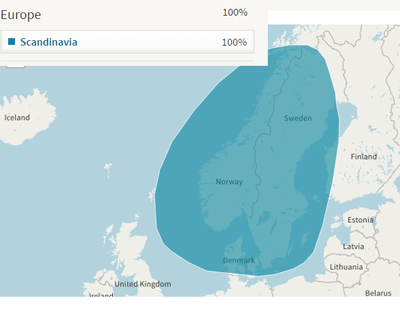
The first release of a new feature, is always exciting but just as often it is also disappointing because it is missing functionality that you expected. I am told that the things I missed the most – search by surname, sorting options – will be implemented, but I did not get a commitment on getting a place to put notes.
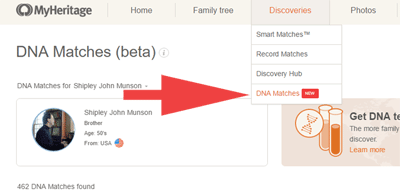 If you previously uploaded your DNA kit, you can now see your DNA matches at myHeritage by clicking on the tab Discoveries and then on DNA Matches in the drop down (the red arrow in the image is mine as usual). When you have more than one kit there is a drop down to select which kit’s matches to view (a tiny down arrow to the right of your name after the words DNA matches for).
If you previously uploaded your DNA kit, you can now see your DNA matches at myHeritage by clicking on the tab Discoveries and then on DNA Matches in the drop down (the red arrow in the image is mine as usual). When you have more than one kit there is a drop down to select which kit’s matches to view (a tiny down arrow to the right of your name after the words DNA matches for).
Your matches appear in an attractive list, each in its own box with some information. My known second cousin John is shown below. Scrolling to the bottom gets more matches. There is no paging yet.
If you have not yet uploaded your DNA then go to your tree and find the person whose DNA test you wish to upload. Click on the words Upload DNA data and then follow the instructions.
MyHeritage announced the release of this DNA matching feature in today’s blog post at
http://blog.myheritage.com/2016/09/dna-matching-now-live/
where they explain that they are using imputation (DNA.land uses a similar technique) to match people from all different companies and chip versions and that they are confident in their accuracy.
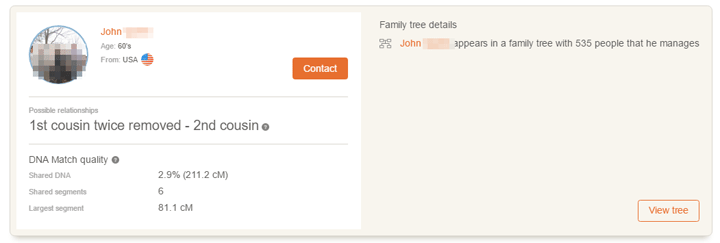
So how do these matches look? My close family looks fine. Dad, myself, my brother, and a second cousin who uploaded his data. Cousin John is listed as a second cousin to my brother and myself but he shares 294.9 cM with a largest segment of 81.5 over at GEDmatch. Somewhat different from the image above where his largest segment is close enough at 81.1 but the total is lower at 211. Perhaps that is because I used my brother’s ancestry kit. Checking my own match with him, there is also less shared DNA at MyHeritage (188cM) than at 23andme (283 cM). Even if we remove the 14.4 cM on the X from that total.
But the less close matches are not looking quite so good.
Continue reading →
 For those of you not familiar with WIKItree, it is a wonderful collaborative world family tree that integrates DNA tests extremely well. Read about it in my article on collaborative world trees.
For those of you not familiar with WIKItree, it is a wonderful collaborative world family tree that integrates DNA tests extremely well. Read about it in my article on collaborative world trees.