Perhaps this post needs the subtitle , “My Perfect Cousin Goes to GEDmatch.”
Most of us can keep track of information in spreadsheets. So how to do that with DNA? Well, the idea is to keep a list of matching DNA segments so that a new match can be compared to your known family members. That way you may be able to see where they fit in.
If you have tested at 23andme, MyHeritage. or Family Tree DNA, you can download your list of matches with their matching DNA segments either directly from your testing company or by using the tools at DNAgedcom. However AncestryDNA does not provide a list of matching segments.

Extract from my Dad’s Master DNA Segment Spreadsheet (click for a larger version)
Why would you want those? The short answer is to figure out which line a new DNA cousin belongs to. For the long answer, read on. For more posts about DNA spreadsheets click here or in the tag cloud, lower right hand column.
 AncestryDNA
AncestryDNA testers can make a DNA segment spreadsheet by using any of a number of utilities at the GEDmatch web site. Start by uploading your raw DNA data (click here for that “how to” post). Your results will usually be ready for full comparisons the next day. Then buy the tier 1 utilities for at least one month ($10).
My preference for making a first spreadsheet is to use the Tier 1 GEDmatch Matching Segment Search. Then I go through the top matches from the ‘One-to-many’ matches report with that spreadsheet as a reference. I add notes on what I discover to my new spreadsheet.
Here is the step by step of what I did for my perfect cousin J.M. whose AncestryDNA results I blogged about in my previous post.
First I uploaded J.M.’s raw DNA results to GEDmatch under my own account and used a pseudonym for her name – Kittys2nd1rJM – which makes it clear to me who she is. Plus anyone who matches her will understand that she is my 2nd cousin once removed. Then I waited until the next day.
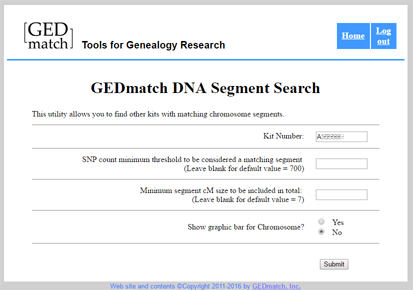 On that next day I clicked on the tier 1 function “Matching Segment Search” and got a form where I had to fill in her kit number (your kit numbers are shown in the third box in the left hand column on your GEDmatch home page). I used the defaults for the SNPs and the cMs. Next I checked the No box next to the “Show graphic bar for Chromosome?” in order to make it easier to copy the results to a spreadsheet. Then I clicked submit and went to the kitchen and made myself a salad. I still had a bit of a wait on my return.
On that next day I clicked on the tier 1 function “Matching Segment Search” and got a form where I had to fill in her kit number (your kit numbers are shown in the third box in the left hand column on your GEDmatch home page). I used the defaults for the SNPs and the cMs. Next I checked the No box next to the “Show graphic bar for Chromosome?” in order to make it easier to copy the results to a spreadsheet. Then I clicked submit and went to the kitchen and made myself a salad. I still had a bit of a wait on my return.
Once the matching segment report completed, I used control-A to select the entire page. Then control-C to copy it to my “clipboard.” I opened my spreadsheet program, OpenCalc from OpenOffice, and pasted (control-V) that data into a new sheet. There were a bunch of extra lines at the top which I deleted as well as two extra lines at the bottom that I deleted.
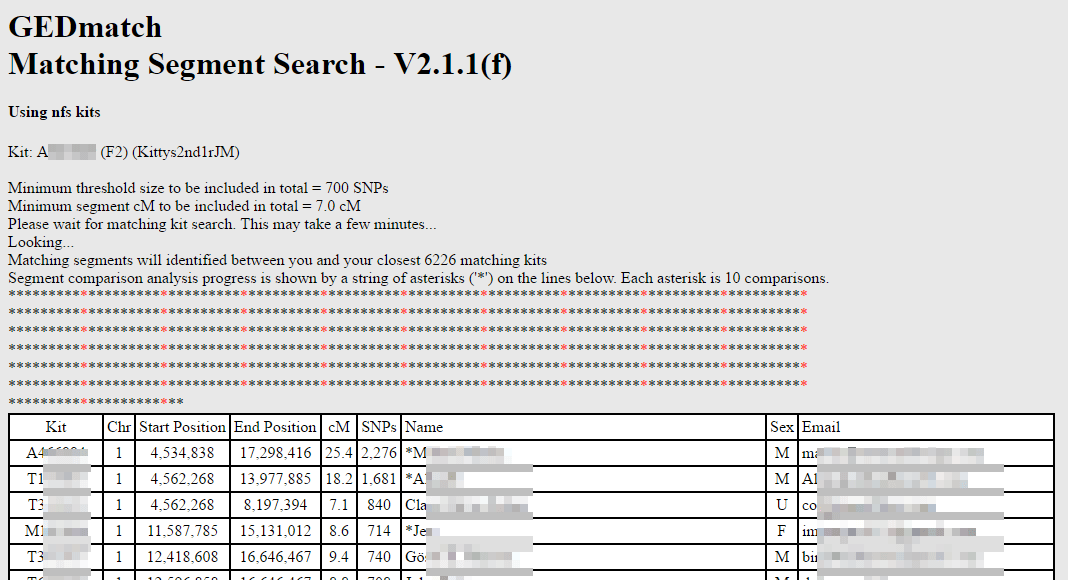
Now I moved the name column to before the chromosome column and I changed the column sizes as needed. I added an initial column for “side” where I will put M, P, or I for maternal, paternal, or IBC (false). Then I add several columns before the email column. One for the company I got the match from, one for the most recent ancestor(s) (MRCA), one for the relationship, and another for notes. These days I mainly use notes for who else matches here. Here is how that looked.

If you DO NOT have other known relatives at GEDmatch, you can skip this next step… I sorted the spreadsheet by the match email address and name and searched for my own email address. Then I added the known MRCA, side, and relationship for all the kits I manage. I also added the same for other known Munson cousins on her list. Then I bolded the names of all the known relatives.
Next I ran a one-to-many report for her kit and looked through her top matches. My family members were matches 1-5 but there was a new match, Naomi, with an M kit number, so a test from 23andme, at position 6. I also spotted a group of the 3rd cousins descended from Neils and Martha Simensen previously found at Ancestry in the top ten, because the email address username was the same as the username at ancestry. So I added the common ancestors and presumed relationship (3C) to all those kits in J.M.’s master spreadsheet, found by searching for the email.
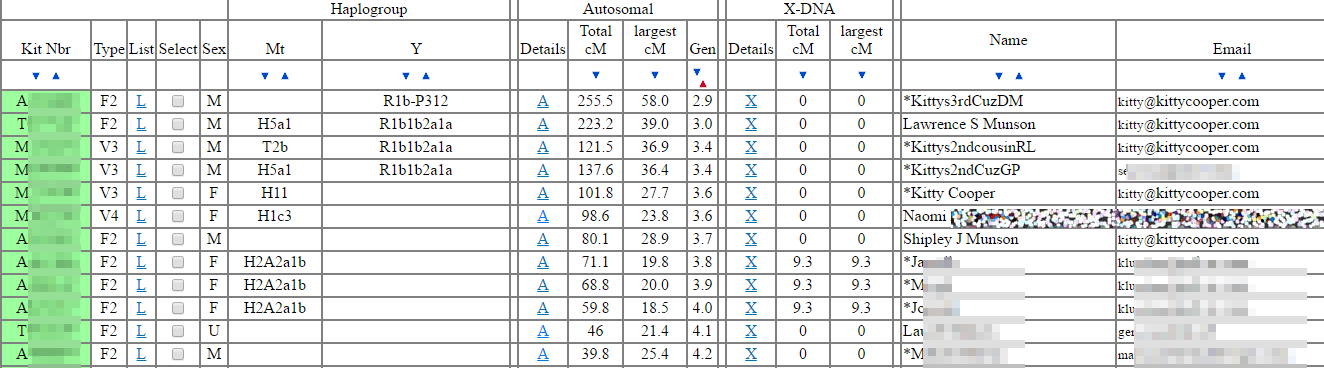
I also checked the other matches that had a gen of 4.5 or less that were kits from Ancestry (kit numbers starting with A) by searching for the name listed or nickname or the username in the email address. Found several of them at Ancestry
. Added those relationships where known.
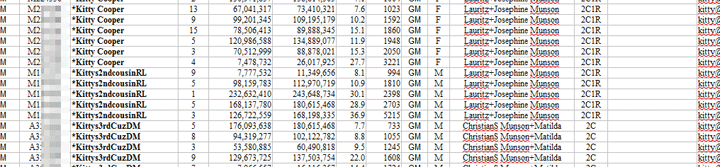
Finally it was time to put the master sheet to work on that Naomi match. I sorted the sheet by chromosome and start position. Then searched through the sheet for Naomi to see if there was anywhere that she overlapped with known relatives. Look what I found.

She overlaps both my 3rd cousin DM (JM’s 2nd cousin) and the Simensen group for a really solid 17cM match at chromosome 19. Since DM is from J.M’s mother’s side and the Simensens are from her father’s side, Naomi should only match one group or the other. A quick one-to-one with DM and one of the Simensen crowd settled the matter: Simensen. I checked Naomi’s kit number at GEDmatch to see if she had uploaded a tree (click here for that post) but no luck; so I sent her an email with my findings.
I will be continuing to use this process with J.M’s other close matches.
Those of you who are coming to the i4gg genetic genealogy conference at the end of October in San Diego, this technique will be part of my talk there …
By the way, I have a template for DNA segment matches that includes the centromere locations in my downloads area.
Another thing you can do with master spreadsheets is to map the DNA of an ancestor. See the one I did for my Wold ancestors. Hoping to do the Munson side soon!
Thank you J.M, your results are a delight to work with.
Just when I think I have enough DNA homework, you give me another challenge! Dang, girl, I’ve got work to do, ;-))
Well I’m excited because this is more or less how I am working, but it certainly begs the point that Ancestry, unlike the other providers, fails to support users in this regard either with segment specific data OR match list exports. (I use Chrome AncestryDNA Helper but it is somewhat flawed and unreliable). Luckily we have Gedmatch, but sadly it used to be that one could actually cut and paste the Matching Segment output including an accurate representation of the graphic. (This is less practical now because my matchlists are too long for efficient cut and paste.)
Either Gedmatch or Excel changed something and now the variable length of the color is lost. Any idea why that happened? Also, is the Gedmatch team eventually going to support .csv, xmls,, or xls versions of its output reports? would that not be cool!
Ancestry caters to the people who want the benefits of DNA testing with much less work. The tree matching is wonderful. It is possible to use that, the ‘in common with,’ and circles to accomplish the goals of the less intense genealogists.
I am grateful to their TV ads which have brought many new testers in and I accept their limitations.
Kitty
Forgot to say that it is the GEDmatch triangulation tool that changes color not the matching segment tool
One thing I do to take advantage of the spreadsheet format is to use conditional logic do things like color code the background of the kit source (e.g. if the kit has an A (Ancestrydna) in it, color it red, blue for 23andme, green for FTDNA) and once the evidence supports coding clusters by paternal or maternal, I set the background color to pale blue or pink – and set it to gray or yellow depending on its status otherwise. I also use the scale logic to change background colors to make sure the biggest segments stand out, etc
I love to use color also, but I do not automate it. I use it to highlight triangulated groups. I started with blue for paternal and beige for maternal but too often they were side by side and I had to vayr it. Later I added a column “side” which is useful for my ancestor chromosome mapping tool. Lots of detailed spreadsheet posts here (click DNA preadsheets in the tag cloud) including one from Jim Bartlett, who now has his own great blog – https://segmentology.org/
Where is the conference? I would love to join. I have a new first (half) cousin on Ancestry.com, neither of us knows our father. After uploading our raw data onto GEDMATCH, it looks like we maybe half sisters!
The conference is in San Diego,weekend after this, see http://i4gg.org/
And that is very exciting news for you! Have you joined DNA detectives at facebook? Have you been to DNAadoption.com and looked through their materials?
Oh how I wish I understood all this stuff. I am doing well to simply find any trace of ancestors through my DNA tests. There is not a lot of living relatives that can give me the insights I am looking for when it comes to the secrets in our past relatives.
I still haven’t figured out how to use any of the chromosome information & the language used in genetics is foreign to me.
Are there any books that break things down in beginner format; like terminology definition & what it means to what we are doing & directions on how to decipher. Something like a do step 1 first, then do step 2, etc.
Any suggestions?
See the book suggestions in my Newbie FAQ http://blog.kittycooper.com/dna-testing/newbie-faq/#__RefHeading__2984_1935651755
I use Excel in a similar way with the addition of a bar graph for GEDmatch Matching Segment. It takes a few seconds to copy and paste an Excel formula and you have a bar graph of each of the matches.
How do I share this very long Excel formula with other Excel users?
Could you post me this formula please, and I’ll ask my IT son if he can show me how to add the graphic bar with this formula. I have some cousins would like me to do this table with the graphic bar for them.
Many, many thanks
Caroline
from Bedford, England
The matching segment tool says it shows a list of your “closest” matches, but then why are the cM’s for each matching person on the low side? I’ve been using the “People who match one or both” tool and then the one-to-one to verify who matches who and on what chromosome segment. Match 2, must match 3, 4, 5, 6, match 3 must match 3,4,5, 6 and so on and keep. Is that the same as triangulation? I don’t understand the Triangulation tool either, but in my mind I’m doing the same thing?
Why would a male have an X match?
All males have one x chromosome that they get only from their mother. Females get an x from their mother and and x from their father (so really from their father’s mother). So you can have an x match with anyone, but you can infer where that match may have come from by taking into account the above facts. More in-depth at https://dna-explained.com/2014/01/02/x-chromosome-matching-at-family-tree-dna/
Thank you for your reply. It kind of threw me off seeing a male with an X. I think he was the only male that did.
Men tend to have far fewer X matches since they only have one X but those are usually true matches. Male to male are always true although small ones may be hard to trace back
On AncestryDNA, I use a table of matches. To start I copy the basic information of a match
F.D. (managed by Someone11)
Member since 2006, last logged in Jan 19, 2018
1 Messages
Remove from your list of matches
Predicted relationship: 3rd Cousins
Possible range: 3rd – 4th cousins
Confidence: Extremely High
Cutting that down to “F.D. (by Someone11), 3rd – 4th, Extremely High” putting that in the first column.
Then in another column put the date Jan 19, 2018
If they have a tree and how many people in another column
Next I put all the matches to that person, in the following columns.
When I have enough matches I allocate a column to group matches numbering each group of matches.
Finally a column for notes.
Long winded I know, especially when Ancestry could do the job, with a little effort.
Gareth
The client from DNAgedcom will collect all that information for you into a matches spreadsheet, the m_ file. Then you just have to delete the extra columns …
When I do the matching segment search, none of my closest relatives show up, though they display the proper results in other searches (my mother comes up with the expected cM relatedness, etc). I think I followed your instructions correctly. It has been about 2 days since I uploaded these datasets from Ancestry. Maybe I need to wait longer?
If you still have a problem, contact support with your kit number, Gedmatch at gmail