
Having just received the Etne, Norway local history books (bygdebuker) for Christmas, I have spent countless hours looking at my ancestors in them. Naturally I have been trying to think of even more ways to use these books.
An idea that came to me was to look at my Dad’s one-to-many X matches at GEDmatch.com and see if I could find a match where I could follow the lines and connect them to Dad’s maternal grandad via those books
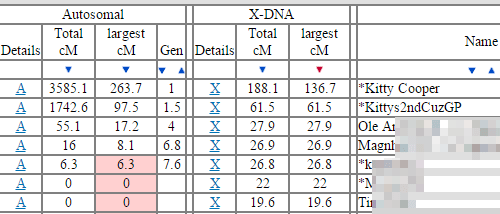
The largest X match he had with an unfamiliar name and email was to *k for 26.8 centimorgans (cMs) and it included a small autosomal match of 6.3 cMs. This seemed promising so I used the user lookup function on my GEDmatch home page and was delighted to see that she had uploaded a GEDCOM.
The GEDCOM number is clickable from the lookup result and it takes you to a page listing the individual. Of course what you really want is the pedigree to quickly scan for relatives in common and there is a button for that at the top of the page. Better is to use the compare 2 GEDCOMs feature from the home page to compare your match’s GEDCOM to your own. Works great if you both have deep trees but I had no luck with that for *k.
Next I clicked on the pedigree button at the top of her individual listing in the GEDCOM which took me to her pedigree page. Nothing jumped out at me and most of them were from Germany.
