The genealogy airwaves have been burning with discussions about losing DNA matches with less than 8 cM shared at Ancestry. For my own family there is no loss, but I feel for those who were impacted. If the site responds faster and better then it was worth it in my opinion. Who can look through some 25,000 matches anyway?
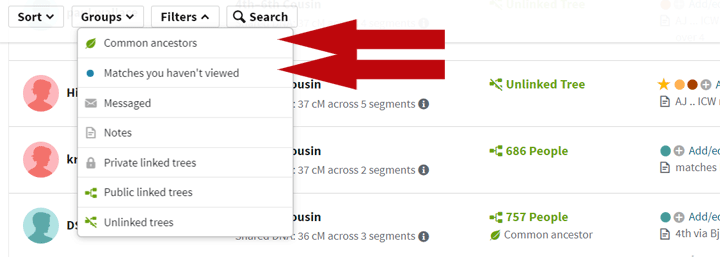
To see how many matches you have left click on the Shared DNA in the list of filters as shown below with my added red arrow.
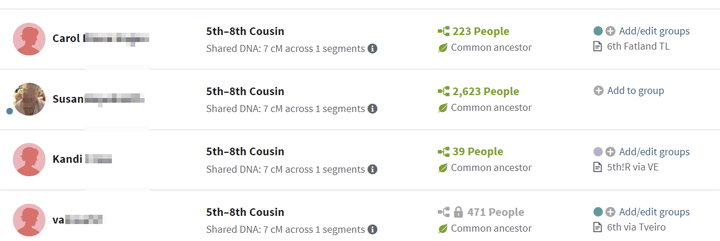
Personally I happened to save 72 of my small matches because I had made a note or grouped them with a colored dot. These included 35 with common ancestors who were grouped; I always group matches with shared ancestors. Whether the shared DNA is actually from those common ancestors is unclear. The half of them from my endogamous Norwegian area may well not be, but the others are probably good.
I liked the suggestion a reader made in a comment on another post that suggested Ancestry look for common ancestors and if found, keep these small matches. I wonder how hard that would be to do for new matches.
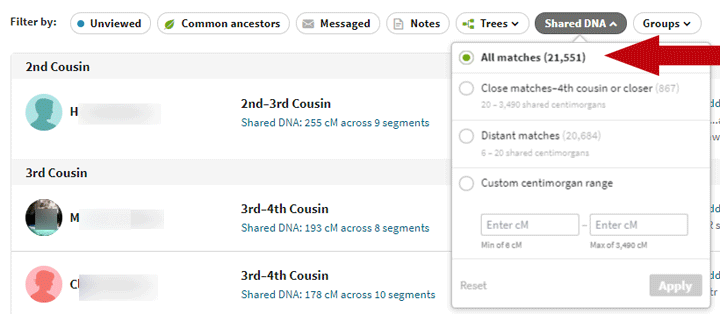
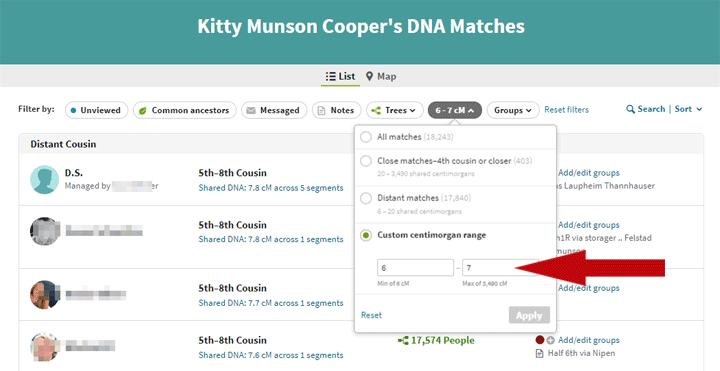
To see my remaining small matches I tried entering a minimum size of 6 and a maximum of 8 but that did not work at all well since all the matches of 8 plus a fraction showed up. So I had to use 7 for the high number as shown below with my added red arrow.
I had collected some statistics for me, my brother, and my tested cousins before the change and added the new numbers just now to look at the differences.
Continue reading