Filing for bankruptcy does not change the day to day operations at a company nor put your data at more risk than before. Plus, as I have said previously, your DNA is not your social security number nor your bank account; it is more like a giant fingerprint that identifies you. Thus I do not recommend deleting your data at 23andme. Many journalists these days try to increase clicks by fear mongering.
My take on these latest developments is that by declaring bankruptcy and stepping down as CEO, Anne E. Wojcicki gives herself one more chance to buy the company she founded with two others and take it private. Her previous two proposals were turned down by each board of directors.
I have listed some more balanced news sources and blog posts at the end of this article.

A short history of 23andme seems in order. Founded by Wojcicki and two others in 2006 [source: wikipedia article], it was the first place to test your personal genome. Their focus was, and always has been, discovering the medical issues in your own DNA, inspired by the search for the cause of Parkinson’s which Anne’s mother-in-law was diagnosed with. Some discoveries have been made and are discussed here.
However, the desire to understand one’s personal health risks was never as strong as the desire to uncover one’s roots, particularly for Americans. Plus the business model of selling DNA kits was never as successful as the model at genealogy-focused companies which include family trees and records once you have a paid subscription. Access to DNA health data for pharmaceutical companies was not lucrative enough to make up the difference.
The lack of financial success was compounded by a data breach that ensued from users who reuse passwords. This allowed bad actors to gain access and create lists of users with Jewish or Chinese ancestry. Although those are reputedly for sale on the dark web, I have not yet heard of any dire outcomes. The result is that all the DNA companies now use two-factor authentication.
Not surprisingly, 23andme stock plummeted. User lawsuits resulted in a settlement. Anne E. Wojcicki, who owns a 49% share, made an offer to buy the company and take it private but the board turned her down and resigned. The next board also turned down the offer she made a few months later. By declaring bankruptcy and resigning as CEO, perhaps she can finally buy it.
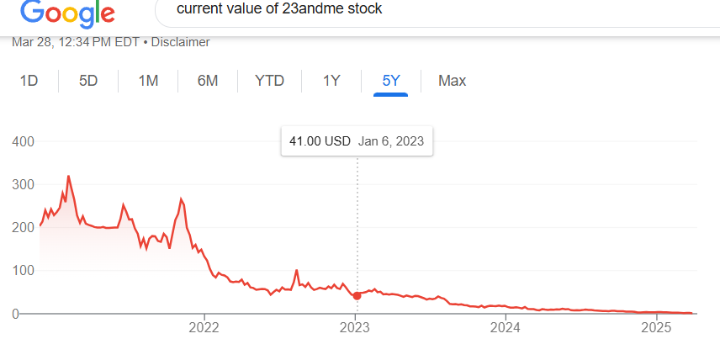
Various news and blog sources:
By the way, the California Attorney General did NOT recommend that you delete your 23andme data, he just explained how and reminded us of the strong California privacy and data laws. Click here for what he actually sent.


 23andme has been in the news this week because its entire board, except its founder, Anne Wojcicki, resigned over her plan to take it private again.
23andme has been in the news this week because its entire board, except its founder, Anne Wojcicki, resigned over her plan to take it private again.