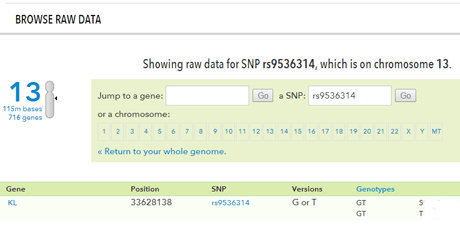
Family Tree DNA has come out with a great way of showing your genetic ancestry for the last several thousand years using a clickable feature-filled map called “myOrigins.” It is listed in the submenu under “Family Finder” on the main menu. You have to have done the Family Finder test, or transferred your autosomal data from elsewhere, to have this feature.
Their data shows that DNA has specific signatures in geographic clusters rather than by modern countries, so your origins are shown in terms of those clusters. In my own case, I am half Norwegian from my Dad and half German from my mother where half of that German was Jewish. I know from other testing companies that I got well more than 25% of my jewish grandfather’s DNA, so I was not surprised to see Jewish Diaspora listed at 32% as 23andme says I have 27% Ashkenazi. Here is the myOrigins picture for me from my transferred 23andme data.
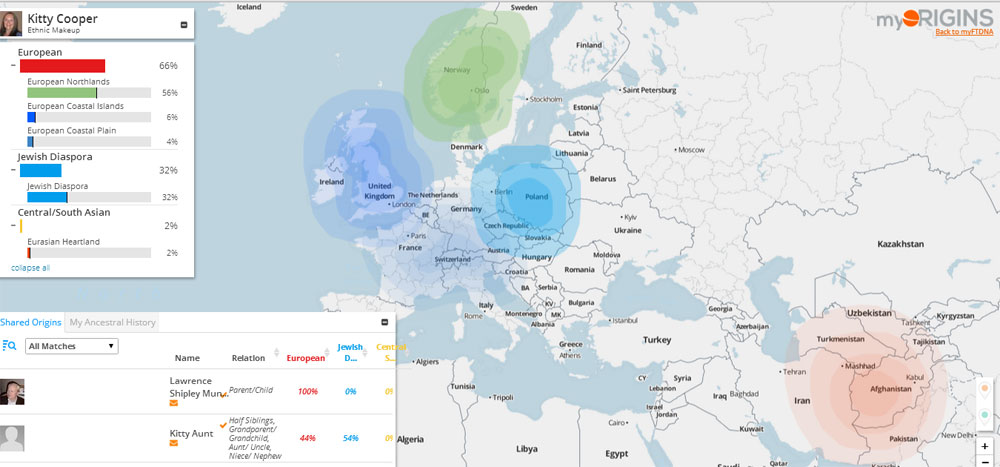
My Genetic Heritage as shown in myOrigins at familytreeDNA
The bottom left box shows your relatives’ percentages in your top three clusters. You can click on any relative to show the location on the map for their furthest back maternal and paternal ancestor (if they have entered that information). Clicking the green (maternal) and red (paternal) dots on the far bottom right will put pins on the map for the furthest back maternal and paternal ancestor locations for all your closest matches who have entered that information. Click on a pin to see the person’s name. Click the red or green dots again to get rid of those pins.
To see a little historical explanation of a specific population cluster you have to expand the larger cluster, for example European, in the box on the top left, and then click on a specific cluster like “European Coastal Plain.” Then some information will be displayed in the bottom left box, under the “My Ancestry History” tab.
Here is part of what it says about my Northlands cluster, “The European Northlands centers on the people of Scandinavia. They thought of their homeland as an island because it is relatively isolated from the rest of the world by the Baltic and other seas. This isolation and later association with the Finnic peoples, however, have changed them in ways that are genetically clear. A sister cluster to European Coastal Plain and European Coastal Islands, the European Northland has developed in moderate seclusion, influenced by the arctic heritage it shares with those from the North Circumpolar cluster.” Since I am shown as well more than half Northern, I have to assume some of that came to my German side as well.
To better understand how to use all the features, I did the online seminar about myOrigins which can be found at the ftDNA library of webinars located at https://www.familytreedna.com/learn/ftdna/webinars/. It was easy to sign up for it and download it and then play it in the “Windows Media Player” where it worked perfectly.
Continue reading →
 This wonderful blog post explains Norwegian naming in great detail.
This wonderful blog post explains Norwegian naming in great detail.